
This is the site of Brant M Cebulla. Pretty awesome.
This blog post will cover the methodology I used to pull data from games.crossfit.com to see what the normal distribution looks like for classic CrossFit workouts, one-rep maxes, sprints and other stuff listed on a CrossFit Games athlete profile page.
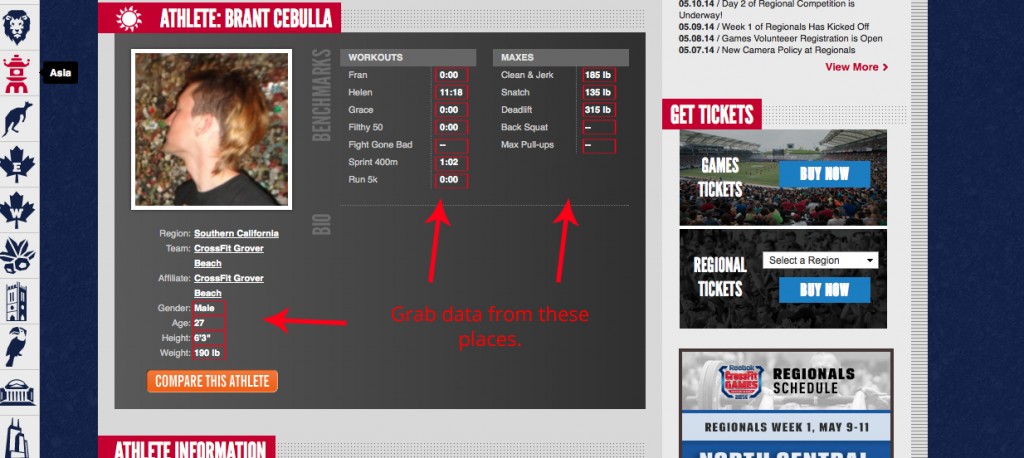
On a CrossFit Games athlete profile page, athletes can self-report their best marks for the following:
Athletes also self-report their gender, height, weight and age.
What I wanted to know is using these self-reported marks, what does the normal distribution look like for these marks? What’s an average time/weight? What’s a good time/weight?
While the goal in working out is to improve your own self, it’s still nice to know how you stack up compared to the rest of the world. Knowing what a weak time/weight is, what’s average and what’s good can help you focus on your weaknesses, help you understand your strengths, and help trainers evaluate their athletes, to better tailor training and ensure safety.
So I needed to pull data from the CrossFit Games’ website. To collect data off of the CrossFit Games’ website, I needed to use a technique called “web scraping.” Web scraping takes a look at web pages and collects specific text/data on those web pages and translates that data collection into spreadsheets and tables. What I needed to do is scrape data off of as many athletes’ pages within reason.
I used software called FMiner. In FMiner, I designed a data extraction project that worked like this:
In theory, this means the project would have loaded the urls of 300 CrossFit teams. However, some of the urls didn’t exist or didn’t have any athletes listed on those teams.
This method led to the extraction of data from 5,376 athletes. Of these athletes, 3,159 were male, 2,217 were female. I exported this data to Excel.
The majority of these athletes did not self-report their marks. After excluding athletes from the data that didn’t report any marks, there were 1,935 athletes, 1,301 of which were male, 634 female.
Notice the much larger percentage of men reporting marks than women. Out of the data I extracted, men made up 58.8% of the pool. Yet, after excluding people who didn’t do any self-reporting, men made up 67.2% of the pool.
This highlights a general limitation with this data. The more enthused, the much more likely to enter into the Open and report data. Since these are people who entered into the CrossFit Open, they are likely a little more skilled than your average CrossFitters. While the Open is designed to appeal to both world class CrossFitters and to novice CrossFitters, there’s no doubt that more experienced and better athletes over represent the Open field.
Furthermore, since people self-report their best marks, the people who take the time to report or actually know their best marks are more likely to be better and more serious athletes than those who don’t report their marks. One-thousand people who know their one-repetition max clean and jerk likely lift more than 1,000 people who don’t know their max or don’t care to report their max.
That being said, this is good data and represents those who enter into the Open generally. In the next couple months I will be going over what this data shows in several blog posts.
Click this button below to see all the blogs/data stemming from this project.